AVR microcontrollers are fascinating to me, and I keep wanting to program them in fun and weird ways, using C++ in particular, as you may have seen in another previous post.
Today, I want to investigate the implementation of coroutines (in fact, more precisely, of collaborative green threads) on AVR.
This is interesting to me because AVR microcontrollers are single threaded. So being able to have multiple “concurrent” tasks is indeed something someone might want to do; at least I want to do it, mostly for fun :3
Coroutines, fibers and green threads
For long have I debated about what to call the stuff I am going to present here. I went with the simple name of coroutine, but there is a discussion to have about that.
A coroutine is sometimes defined as “a routine you can pause”. I find this statement a bit misleading, as it does not define what “to pause” a routine means, neither who is pausing the routine.
Bluntly, a coroutine looks like a normal routine (a function, a procedure, whatever), except it may include a special operation that basically yields control back to the caller. The caller may then do something else and give the control back to the coroutine, who will resume its execution from where it stopped.
The special operation is often called yield. When the coroutine encounters the yield instruction, someone (the system for instance) takes a detailed snapshot of the state the coroutine has found itself in, and then goes do something else, until it decides to resume the coroutine, in which case the coroutine is put back in the exact same state as the snapshot. Is that not neat?
Now coroutine is a general term for routines that can interrupt themselves (yield has always to be called by the coroutine, this is important); but their uses is widespread and diverse. One of such uses are fibers.
A fiber is sometimes referred to as a “lightweight thread”. A thread, well, is sometimes referred to as a “lightweight process”. And a process, well, is a process.
More seriously though, a process is basically what holds a program during its execution. It is composed of the program plus the execution context (variables, where the program is at, etc.). A machine is usually executing multiple processes “at the same time”, managed by a system, your OS for example (although simultaneity is a vast and complicated concept in computer science, to us humans it looks like it is at the same time).
Within a process, the program may make use of several threads, which are tiny execution environments that look like processes, except they are managed mostly by the container process, rather than by the system.
Something very important here is that, for processes and threads, management is exterior: the system manages the processes, i.e. decides which is being executed at what time, and the same (kinda) goes for threads. We call that preemptive behaviour: the system/process preempts the process/thread.
A fiber is a lightweight thread in the sense that it looks and achieve similar things to a thread (i.e., concurrency); but unlike threads, a fiber is not managed by a container thread. Instead, a fiber manages itself, using yield-type constructs. We say that fibers are cooperative: they themselves “decide” when they have done enough and transfer the control to another fiber.
Sometimes it is said that fibers are to threads what threads are to process, meaning that fibers are “the subdivision” of threads just like threads are “the subdivision” of processes, but I do not fully agree with that.
Fibers are, in essence, a way to do lightweight concurrency when no concurrency is available, be it because we are already in a thread or because the system is not multitasking.
For this reason, we sometimes talk about green threads.
Basically, although I said threads are managed by the process, they are, in fact, usually constructs of the system. This is true for various reasons, one of them being that threads are often physical (x86 CPUs feature cores that are divided into threads).
Green threads are threads that are not handled by the system at all, and are fully managed by the process, in general in a cooperative way. For this reason, all fibers are green threads, but all green threads are not fibers.
Similarly, coroutines may be used to implement green threads, but not only; in fact, the term green thread may also denote threads that are managed by a virtual machine.
All of that to say: in the following, I will talk about stuff that I will call coroutines mostly. I do not think they are fully generalized coroutines, however, and are more akin to fibers, but they may be used in other ways…
In other words, this is all debatable and complicated, let us settle on the use of the word coroutine, and we will be fine.
AVR
AVR is a family of microcontrollers, that are basically simple computers in a chip. It is fairly recent (2016) and quite in use, including by the DIY community.
I use AVR microcontrollers because they are cheap, powerful and quite easy to handle, both design-wise and programming wise. They are based on a RISC-type architecture, which means they have a simple assembly language (unlike, say, x86 architectures…), which make it is easy to program with both high- and low-level languages, whichever is needed.
I will not go too much into detail about the technical refinements of AVR microcontrollers; for our purpose, the main thing we need to talk about is the “modified Harvard” architecture they are based on, as well as a few things about their general behaviour.
Harvard and von Neumann architectures
If you did not know, the world of computers is divided into two important categories: von Neumann and Harvard.
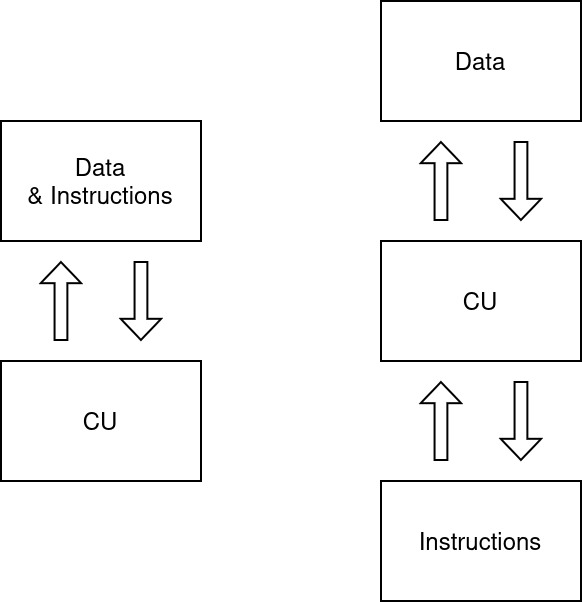
von Neumann (left) vs. Harvard (right) architectures
As a preamble, remark that, for a computer, everything is basically just numbers. This applies to the things a computer does (the instructions) and to what it is applied (the data). In effect, there is no difference between data and instructions, save for the fact that the latter can be understood by the central processing unit and corresponds to some behaviour. So, the question is the following: should we store data and instructions in the same place, since we can?
We use the term von Neumann (in reference to the von Neumann to refer to architecture where the control unit (the “brain” of the machine) is hooked up to only one memory space, that thus contains both data and instructions. Most modern complex CPU you find in consumer electronics such as the computer or smartphone you are using to read these lines follow the von Neumann architecture. The main reason for that is probably cost, in addition to a more uniform way of designing things, as you require only one type of memory.
On the other hand, when we separate data and instructions, we talk about a Harvard architecture. The Harvard architecture nowadays is mainly found in embedded applications and DSPs, applications that benefits from the possible parallel access to data and instructions.
AVR microcontrollers follow a variant of the latter, where a part of the instruction memory is mapped to the data memory, allowing in-system programming, but that is beyond the point.
Pipeline, jumps and stack
AVR follow a simple two-stage pipeline: 1) fetch an instruction, and 2) decode and execute the instruction. The current instruction being executed is pointed at by the program counter (PC). Basically, the PC is a special 16-bit (or 22-bit) register that contains the address of the current instruction in the instruction memory.
Non-control flow instructions such as arithmetic and memory fetching increment the program counter, while control flow instructions such as branches and jumps set the PC to a given value.
Among the many special “registers” available to the developer, AVR microcontrollers feature a 16-bit stack pointer (SP). A stack is basically all we need to declare variables, and so it is very handy that there is one integrated in the architecture.
The behaviour of the stack is two-fold:
- It is used to store a local variable
- It is used to store the return address of a call to a subroutine
Subroutines in AVR assembly are handled using call (and its variants) and
ret. Basically, call pushes the address of the next instruction (PC + 1)
onto the stack and jumps (= changes PC) to a given number, and ret pops that
address out of the stack and uses it to jump back to the instruction next to the
call.
This simple system allows us to have many levels of nesting when calling functions, which would not be possible if the return address was stored, say, in a register.
Note that, as often, the stack behaves decreasingly: the stack base (the
initial stack pointer) is a high address, and it decreases every time we push.
On AVR with most compilers, the stack pointer is initialized at the end of the
SRAM (at 0x7FFF usually).
Besides call, one can modify the PC by using jmp and its variants. The
principle of jmp is the same as call except it leaves the stack untouched.
We will take note, in particular, of the ijmp instruction, that jumps to the
address in the instruction memory specified by the register pair r30:r31 (also
called Z).
The requirements
As always when I am about to delve in a subject, I try to set a goal to myself, under the form of a set of loose requirements, that are basically what I want to be able to do.
So here we go. I want to be able to schedule coroutines. Now the difference between coroutines and normal subroutines is a but fuzzy for now, but that is alright.
Coroutines shall be able to yield, so I want a yield symbol somewhere. When
a coroutine yields, its state is saved and an other coroutine is resumed (or
launched). What is this state? We will have to figure that out. Who “resumes”
the coroutine and manages all that? We have several possibility here, that are
mostly technical; for now, let us call the mysterious entity pulling the strings
the scheduler.
This scheduler must let me schedule coroutines, i.e. specify what coroutine are in the pool of coroutine that are collaborating together. It must not resume a coroutine that has exited.
Oh by the way, I will use (C/)C++ to program all that, because I need access to both inline assembly and high level language features (and because I do not hate myself that much, in fact).
Okay so this is our basic requirements. Still a lot of holes to fill in, but I think with that we can start to write a simple test program:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
COROUT(f1) {
uint16_t count = 0;
while (true) {
count = count + 1;
if (count < 5000)
PORTC_OUTCLR = 0x01 << __current_pid;
else
PORTC_OUTSET = 0x01 << __current_pid;
yield();
}
}
COROUT(f2) {
uint16_t count = 0;
while (true) {
if (RTC.CNT % 4 == 0)
count = count + 1;
if (count % 4 == 0)
PORTC_OUTCLR = 0x01 << __current_pid;
else
PORTC_OUTSET = 0x01 << __current_pid;
yield();
}
}
COROUT(f3) {
while (true) {
if (RTC.CNT % 16 == 0)
PORTC_OUTCLR = 0x01 << __current_pid;
else
PORTC_OUTSET = 0x01 << __current_pid;
yield();
}
}
int main(void) {
CLKCTRL_MCLKCTRLA = CLKCTRL_CLKSEL_OSCHF_gc; // (default) high freq oscillator internal clock
CLKCTRL_OSCHFCTRLA = CLKCTRL_FRQSEL_20M_gc; // 20MHz internal clock
PORTC_DIRSET = 0x0F; // C0-3 outputs
PORTC_OUTSET = 0x0F; // C0-3 high
// RTC setup
RTC.CLKSEL = RTC_CLKSEL_OSC1K_gc;
RTC.PER = 0xF000;
RTC.CTRLA = RTC_PRESCALER_DIV32_gc | 0x01;
_delay_ms(250);
init_scheduler();
PORTC_OUTCLR = 0x01;
schedule(f1);
schedule(f2);
schedule(f3);
exit();
PORTC_OUTSET = 0x01;
return 0;
}
|
I make use of AVR-specific stuff because at the end of the day I want to be able to observe the system, but you are not required to understand anything about AVR to tag along (hopefully).
The principle of this test program is rather straightforward:
- I use the Real Time Counter (RTC) of my AVR to count at a given period and with a given subdivision
- I imagine I would have to initialise the scheduler, with
init_scheduler - Then I imagine I may be able to schedule some coroutines; coroutines are
declared using that
COROUTINEmacro we will have to define, and scheduled usingschedule. - I imagine that the current process is itself a coroutine (one that is not
launched by the scheduler), so I
exitit, which yields control to the other coroutines. - Coroutines
f1,f2andf3execute “concurrently”. They have local variables, so we need to take care of that. What they do, basically, is flip a bit on one of the output of the AVR microcontroller, causing a LED to go on and off at a (hopefully) regular and perceptible speed.
I use a board I made with 4 LEDs; in theory, we should see the second, third and fourth ones dancing independently, if that program were to work…
Step 1: the state of a coroutine
When I say that the state of a coroutine needs to be stored, what exactly needs to be stored, in fact?
If you have been following, you will know that one thing is for sure, we need to store the program counter, so we can return to it later. Another thing that we need to store is the stack pointer of a coroutine, so that the coroutine may be able to retrieve local variables whenever resumed.
By the way, we need to manage stacks so that they do not interfere with one another. Basically, each coroutine has its own stack (and even, its own memory region) in the SRAM (the data memory), and it is the role of the scheduler to handle that.
We will also need a status information on each subroutine: which one is ready but not yet launched, which one is running, suspended, or stopped (exited).
So, here is the process data we can go with:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
enum class process_status : uint8_t { LOADED = 0, RUNNING = 1, SUSPENDED = 2, STOPPED = 3, EMPTY = 255 }; struct process_metadata { schedulable_t pc; process_status status; uint8_t pid; uint8_t spl; uint8_t sph; }; |
Nothing too complicated. Note that we also store the “pid” (process/coroutine
identifier) of each coroutine, although this is not needed. Notice also that the
stack pointer is given as two 8-bit fields rather than one 16-bit field; this is
because it is much easier to handle that way, since the stack pointer “register”
is split into low (SPL) and high (SPH) anyway.
The status field is defined using an enumeration. EMPTY means the coroutine
“spot” has not been loaded with anything, LOADED that it has been loaded with
a function but not launched yet, RUNNING that it is currently running,
SUSPENDED that it is not running but can be resumed, and STOPPED that it was
exited and should not be re-scheduled.
The last point to discuss here is the schedulable_t field. We could save the
PC as a 16-bit field, i.e. typedef uint16_t schedulable_t, but I find it funny
to keep this idea of executable part of the memory within the type. Why not
store the PC as a function pointer? Which is essentially an address in the
instruction memory space!
Now what would be the exact type of a schedulable coroutine? I think that 1) a coroutine does not return anything in general (otherwise, who/what will handle the return value?) and 2) at least for now, I do not think an argument is relevant either.
So, here is the type of a coroutine:
1 |
typedef void(*schedulable_t)(void); |
Let us define the COROUTINE macro we need at the same time; we will come back
to it should we need it:
1 |
#define COROUTINE(name) void name (void) |
This covers what each coroutine is associated to; but what does the scheduler need? Well, for one, it needs an array of every coroutine it manages. We are on a microcontroller; we have 16kB of data memory, so we are not doing a fancy data structure this time around. In fact, we will fix the number of coroutine that can be scheduled.
Next, we need the PID of the current coroutine (which is an index in the array of coroutine). We will make this PID evolve when we want to change the coroutine being executed.
With all that, let us define a few static variables:
1 2 3 4 |
#define NUM_PROC 4 // Number of coroutines static process_metadata __procmd[NUM_PROC]; static uint8_t __current_pid = 0; |
Note that static variables are stored at the beginning of the SRAM (starting at
address 0x4000 in general), so we will have to keep that in mind when
allocating memory regions to each coroutine.
Memory regions and scheduler initialization
The best way to have each coroutine use a different stack will be to set up the
stack pointer ourselves with the values of spl and sph. Now what values
should we initialize these two with?
Since the number of coroutines is fixed, we can divide the SRAM into NUM_PROC
equal parts, and give each coroutine a slice of the cake, starting from high
addresses (since the main process starts with SP = 0x7FFF).
Knowing that, we can initialize each process metadata of the array, and thus write the scheduler’s initialization:
1 2 3 4 5 6 7 8 9 10 11 12 13 |
void init_scheduler(void) { for (uint8_t i = 0; i < NUM_PROC; i++) { __procmd[i].pid = i; __procmd[i].status = process_status::EMPTY; __procmd[i].pc = 0; // "Allocate" a piece of RAM uint16_t sp = RAMEND - ((uint16_t) i) * (RAMSIZE / NUM_PROC); __procmd[i].spl = (uint8_t)(sp & 0x00FF); __procmd[i].sph = (uint8_t)(sp >> 8); } // Process/coroutine 0 is the "main fiber" which is already running __procmd[0].status = process_status::RUNNING; } |
Now notice that the last process will have a bit less RAM available, because of the static variables, but we will have to live with that :(
Step 2: retrieving the coroutine state
The first step in yield is to retrieve the coroutine’s state. The main issue,
as hinted before, is to retrieve the PC.
Ideally, yield would be called by the coroutine; and by that I really mean
called, meaning the PC (or rather PC + 1, which is not a problem, quite the
contrary) is on the stack.
So we can pop twice to retrieve the PC, and store it in pc. This cannot be
done easily in C/C++, without using inline assembly:
1 2 3 4 5 6 |
asm volatile( "pop __tmp_reg__\n\t" "std %a0+1, __tmp_reg__\n\t" "pop __tmp_reg__\n\t" "std %a0+0, __tmp_reg__" :: "b" (&(__procmd[__current_pid].pc))); |
I will not go into too much detail about inline ASM,
but what is going on basically is that we pop from the stack into a temporary
register, and then store the content of that register to the given address. We
need to do that in two steps because the PC is 16 bits. The use of b here
allows us to tell the compiler to store the PC in our pointer using one of the
Y or Z register (do not fret about it, this just means it is going to work!
Hopefully).
The next step is to retrieve the current stack pointer. It would also be good to retrieve the Status Register (SREG) that contains the flags of the CPU, and is actually accessible directly!
1 2 3 4 5 6 |
asm volatile( "in __tmp_reg__, __SREG__\n\t" "push __tmp_reg__\n\t" "in %0, 0x3d\n\t" // Get stack pointer "in %1, 0x3e" : "=r"(__procmd[__current_pid].spl), "=r"(__procmd[__current_pid].sph) :); |
The stack pointer is a “fake” register, located at an actual memory point
(0x3d, 0x3e), which we can access using in to read from it and out to
write to it (they are called I/O registers, in fact). Same thing goes for the
status register, __SREG__.
(notice how we may do two in into our two variables spl and sph, quite
convenient!)
Step 3: relinquish control and resume
Next, yield will put the coroutine into suspension if it was running (if it was
not, it was typically stopped), and look for the next schedulable coroutine.
That part is reasonably easy to write:
1 2 3 4 5 6 7 8 |
do { __current_pid++; if (__current_pid >= NUM_PROC) __current_pid = 0; status = __procmd[__current_pid].status; } while (status != process_status::LOADED // It is a good idea to define status as a static variable && status != process_status::SUSPENDED); __procmd[__current_pid].status = process_status::RUNNING; |
Once we found that new PID, we need to resume the associated coroutine, or
launch it if it was not launched already. In both cases, we will end up doing a
ijmp to the value of pc; but in the latter case, we just need not to pop the
status register since it was never pushed to begin with.
So here is what we can write:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
asm volatile( "out 0x3d, %0\n\t" // Set stack pointer "out 0x3e, %1" :: "r"(__procmd[__current_pid].spl), "r"(__procmd[__current_pid].sph)); if (status == process_status::LOADED) { } else { // == SUSPENDED asm volatile( "pop __tmp_reg__\n" "out __SREG__, __tmp_reg__\n" ::); } asm volatile( "ijmp" :: "z"(__procmd[__current_pid].pc) : "memory"); |
The last inline ASM part is really the magic sauce here. It loads the address of
the PC into the Z register, and does the ijmp, which jumps to precisely
where the Z register tells it to jump!
If the routine was not launched, pc contains the address of the beginning of
the function, so this looks like a normal (stackless) call!
A note here if you are familiar with inline ASM, I use memory as clobber
because otherwise the compiler kept re-ordering my ASM blocks (not entirely sure
why).
Anyway, that is it, we wrote our yield function! Just one more remark: this
function has to be called regularly. It must NOT be inlined, otherwise the PC we
retrieve will be wrong!! Also, we should probably get rid of the function’s
prologue and epilogue to avoid SP manipulation, typically. We can both of that
using compiler attributes.
We can also write the exit function, which sets the coroutine’s status to
STOPPED and then calls yield, as normal. Now that function better be inlined
to avoid stack manipulation at all (including the one when call happens):
1 2 3 4 |
inline void __attribute__((always_inline)) exit(void) { __procmd[__current_pid].status = process_status::STOPPED; yield(); } |
For the same reason, coroutines should not have a prologue which would temper with the SP, so:
1 |
#define COROUT(name) void __attribute__((naked,noinline)) name(void) |
Step 4: schedule functions
And finally, we can write a simple function that takes schedulable coroutines
and allocate them a spot in the array of coroutines we prepared (arguably
schedule is not a good name for it but oh well):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
uint8_t schedule(schedulable_t f) {
uint8_t pid = 0;
while (pid < NUM_PROC // Find next free spot
&& __procmd[pid].status != process_status::EMPTY
&& __procmd[pid].status != process_status::STOPPED) {
pid++;
}
if (pid >= NUM_PROC) { // No spot found
return 0xFF;
}
__procmd[pid].status = process_status::LOADED;
__procmd[pid].pc = f;
return pid;
}
|
And voilà! Simple as that!
Step 5: enjoy the result!
And now a bit of compiling and linking, and generating a .hex file, all of
that using avr-gcc’s tool chain and…
(please do not mind the horrendous solder job this is my prototype board)
There is actually one last catch, in fact; I had to tinker a bit more to get that result, and what I had to do is to disable optimization for the coroutines:
1 |
#define COROUT(name) void __attribute__((naked,noinline,optimize("O0"))) name(void) |
(I am not really sure why to be frank)
Conclusion
I will be honest, I almost cried when I saw the LEDs blinking like that. I did
not go into detail about it but I took me three whole days to debug all that
mess, generating assembly, objdump-ing, again and again and again…
But the solution works! Is it robust? Probably not. There are a number of caveats with it, starting with the fact that registers are not saved. To me this is not a scheduler thing though, in the sense that it should be taken care of by the user; but this requires very precise memory management, which is not ideal…
In the end, it was a great deal of fun working on green threads. I am also glad I had an AVR board available to do it with AVR; I would never do that with x86, ha ha. I like how there is, in fact, no real scheduler (as in, no scheduler “entity”); rather, coroutines manage themselves, and yield does the heavy-lifting, it is quite neat imo.
Anyway, I hope you learned a thing or two today :3